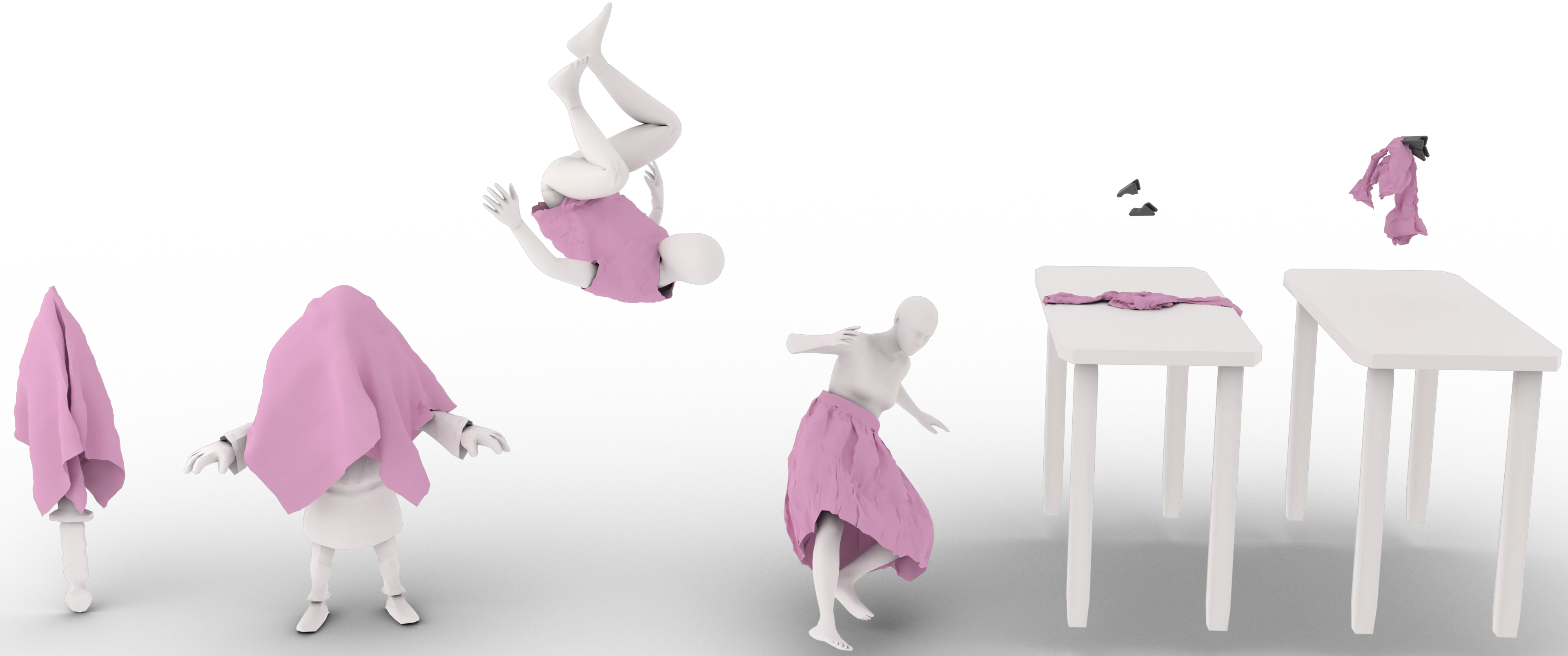
ClothTransformer generalizes to unseen test cases across diverse scenarios. Left two: Diverse Object Collision — cloth falling onto unseen rigid objects (sword, character). Middle two: Human Garment — unseen body, garment, and animation combinations. Right two: Robotic Manipulation — unseen cloth meshes grasped by a robotic gripper. Notably, across all scenes, a single unified Transformer handles diverse cloth dynamics without per-scenario fine-tuning.















